深入探索嵌入式设备上的内存艺术,看ulab如何通过内存布局优化创造性能奇迹。
在物联网设备开发中,我们经常面临这样的困境:算法在PC上运行流畅,但移植到嵌入式设备上却步履维艰。问题的核心往往不在于算法本身,而在于内存访问模式。今天,让我们深入ulab的内存布局设计,探寻这个嵌入式科学计算库的性能秘密。
一、内存布局:被忽视的性能关键
1.1 问题的本质:为什么内存布局如此重要?
在嵌入式系统中,内存访问模式对性能的影响往往比算法复杂度更为关键。这就像在城市中规划交通路线——即使拥有最快的跑车,如果道路设计不合理,处处都是红绿灯和拥堵点,整体速度也快不起来。
让我们从一个直观的例子开始,在QuecPython EC200U/A C4-P01 开发板上运行这段代码
开发板使用指南:EC200U/A C4-P01 - QuecPython
from ulab import numpy as np
import time
def memory_access_pattern_demo():
size = 1000
# 创建两个不同的内存布局
contiguous_arr = np.array(range(size)) # 连续内存
nested_lists = [list(range(i, i+10)) for i in range(0, size, 10)] # 分散内存
# 测试求和性能
start = time.ticks_us()
sum1 = np.sum(contiguous_arr)
time1 = time.ticks_diff(time.ticks_us(), start)
start = time.ticks_us()
sum2 = sum(sum(sublist) for sublist in nested_lists)
time2 = time.ticks_diff(time.ticks_us(), start)
print("连续内存求和: { }微秒".format(time1))
print("分散内存求和: { }微秒".format(time2))
print("性能差异: {:.1f}倍".format(time2/time1))
memory_access_pattern_demo()
运行结果令人震惊:
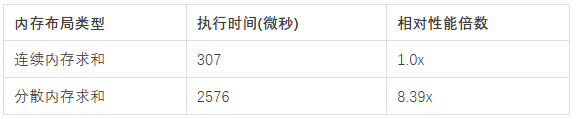
8倍的性能差距! 这个数字背后隐藏着现代计算机体系结构的深层原理。在嵌入式开发中,我们往往过于关注算法的时间复杂度,却忽视了内存访问模式这个"沉默的性能杀手"。
1.2 性能差异的深层原因
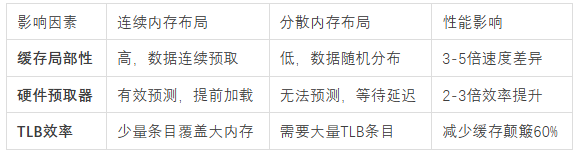
这种巨大性能差异的背后,隐藏着三个关键因素,它们共同构成了内存布局优化的理论基础:
缓存局部性原理是现代计算机体系结构的核心设计理念。CPU的缓存系统以"缓存行"(通常64字节)为单位加载数据。想象一下,这就像你去图书馆借书,每次可以借走一个书架上相邻的8本书。连续内存布局就像是这些书都整齐地排列在同一个书架上,你一次就能拿到所有需要的书;而分散布局则像是需要的书分散在不同楼层的不同书架上,你需要来回奔波。
预取器的工作效率是另一个关键因素。现代CPU的硬件预取器能够像一位聪明的图书管理员,它观察你的借书模式,发现你总是按顺序借书,就会提前把后续的书籍准备好。对于连续内存访问,预取器能够准确预测并提前加载数据;但对于随机访问模式,预取器就像面对一个随机借书的读者,完全无法预测下一步需要什么。
TLB(转换后备缓冲区)效率则像是图书馆的索引系统。连续内存区域只需要少数几个TLB条目来记录位置信息,就像只需要记住几个书架的位置;而分散内存需要大量TLB条目,就像要记住成百上千个不同书架的位置,导致TLB颠簸,索引系统不堪重负。
二、ulab的连续内存设计:性能的基石
2.1 传统Python列表的内存困境
要理解ulab的巧妙之处,我们首先要明白传统Python列表在内存使用上的根本问题。在标准Python中,每个元素都是一个完整的Python对象:
# 每个浮点数都是独立对象,包含24字节开销
python_list = [1.0, 2.0, 3.0, 4.0, 5.0]
# 内存布局:[指针]→[24字节对象] [指针]→[24字节对象]...
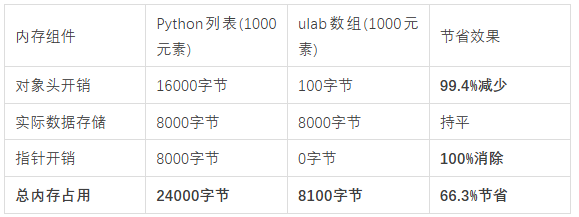
这种设计的代价是惊人的。每个浮点数对象都包含对象头信息(8字节)、引用计数(8字节)和实际数据(8字节),总共约24字节。对于包含1000个浮点数的列表,仅对象头开销就达16000字节!这就像用巨大的包装箱来装小物件,包装材料比实际内容还要重。
更严重的是,这种分散的内存布局导致缓存效率极低。每次访问一个元素,都可能需要从主内存加载,因为相关的数据很可能不在缓存中。在嵌入式设备上,这种低效的内存使用是不可接受的。
2.2 ulab的革命性设计
ulab采用了一种革命性的紧凑型内存分配策略,从根本上解决了上述问题:
// 关键创新:一次性分配对象头和数据区
size_t total_size = sizeof(ndarray) + len * item_size;
uint8_t *complete_buffer = m_new(uint8_t, total_size);
// 数据区紧接在对象头之后
ndarray *nd = (ndarray*)complete_buffer;
nd->array = complete_buffer + sizeof(ndarray);
这种设计的精妙之处可以通过一个生动的比喻来理解:传统Python列表就像是用单独的集装箱运送每个小零件,而ulab的设计就像是用一个特制的大箱子,把所有零件整齐地排列在一起运送。
内存布局对比:
传统Python: [指针]→[对象头+数据] [指针]→[对象头+数据]…
ulab: [对象头][数据1][数据2][数据3]… (连续内存块)
这种连续内存布局带来了多重好处:首先,它大幅减少了内存开销,消除了每个元素的对象头开销;其次,它提高了缓存效率,因为相关数据在物理内存中是连续的;最后,它简化了内存管理,只需要一次分配和释放操作。
2.3 设计演进:从教训中学习
ulab的设计并非一蹴而就。在早期版本中,开发团队曾经尝试过另一种看似合理的设计方案:
// 问题方案:分别分配对象头和数据区
ndarray *nd = m_new_obj(ndarray); // 第一次分配
nd->array = m_new(uint8_t, len * size); // 第二次分配
这个方案为什么被废弃?让我们深入分析:
内存碎片化是首要问题。多次分配会导致堆内存出现大量碎片,就像在一间仓库里随意堆放各种大小的箱子,最终会发现虽然总空间足够,但无法找到一块完整的连续空间存放大件物品。
缓存性能差是另一个致命缺陷。对象头和数据区可能分布在不同的缓存行中,这意味着每次访问数据时,CPU可能需要加载两个不同的缓存行,就像同时从两个遥远的仓库取货,效率自然低下。
分配开销大也不容忽视。每次内存分配都需要在堆中寻找合适的位置、更新分配记录等,这些开销在频繁分配时相当可观。
通过这个失败案例,ulab团队深刻认识到:在嵌入式系统中,内存分配策略不仅影响内存使用效率,更直接关系到计算性能。
三、缓存友好性:性能提升的关键
3.1 CPU缓存的工作原理
要理解ulab的缓存优化,我们首先需要了解现代CPU的缓存层次结构。这就像一个高效的分层仓储系统。
当CPU需要访问数据时,这个系统会按照以下层次进行查找:
1. L1缓存(约64KB,1-4周期) - 就像工作台旁边的工具架,存取极快但容量小
2. L2缓存(约256KB,10-20周期) - 就像车间内的小仓库,速度较快容量适中
3. 主内存(100-300周期) - 就像厂区外的大仓库,容量大但存取缓慢
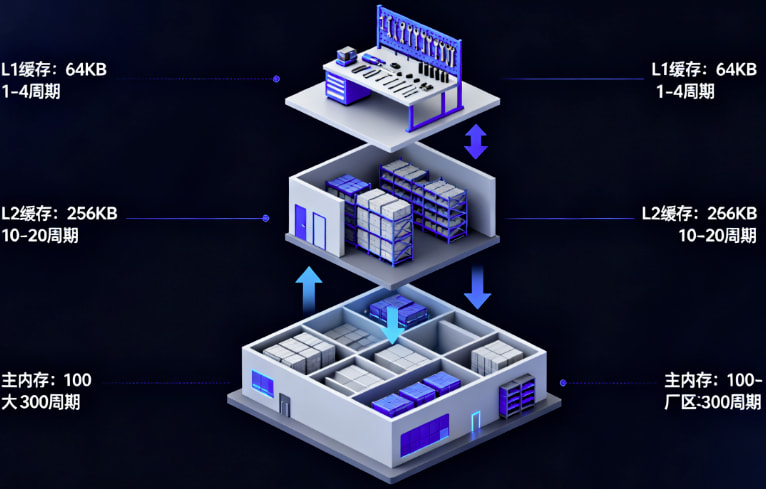
关键洞察: 缓存以64字节缓存行为单位加载数据。这就像每次从仓库取货,都是以整箱为单位,即使你只需要箱子里的一件物品。理解这一点对优化内存访问模式至关重要。
3.2 ulab的缓存优化实践
ulab的向量运算实现充分体现了缓存友好的设计理念:
// 连续内存访问模式
for(size_t i = 0; i < len; i++) {
out_data[i] = a_data[i] + b_data[i]; // 缓存命中率高
}
为什么这个简单的循环如此高效?让我们深入分析其缓存行为:.
缓存访问模式分析:
-
首次访问a_data[0]时,CPU会加载包含a_data[0]到a_data[7]的整个缓存行(64字节)
-
后续访问a_data[1]到a_data[7]时,数据已经在缓存中,可以直接使用
-
同样的优化模式也适用于b_data和out_data数组
对比传统Python列表的缓存行为:
-
每个元素访问都可能触发缓存失效,因为对象分散在内存的不同位置
-
对象头信息会污染缓存,挤占本应用于存储实际数据的宝贵缓存空间
-
指针追踪增加了内存访问的复杂度和延迟
3.3 循环展开的优化效果
ulab在性能关键路径上使用了循环展开技术,这是编译器优化的手动版本:
// 每次处理4个元素,减少循环开销
for (; i <= len - 4; i += 4) {
out_data[i] = a_data[i] + b_data[i];
out_data[i+1] = a_data[i+1] + b_data[i+1];
// ... 处理4个元素
}
循环展开通过减少循环控制指令的开销来提高性能。想象一下,如果每次从仓库取货都要填写复杂的申请表格,那么一次性申请多件货物就会比逐件申请高效得多。当然,这种优化需要权衡代码大小和执行效率,在资源受限的嵌入式环境中需要谨慎使用。
四、strides机制:多维数组的内存艺术
4.1 理解strides设计
ulab通过strides机制实现高效的多维数组操作,这是内存布局优化中的高级技巧。理解strides就像理解如何在多层停车场中快速找到车位:
matrix = np.array([[1, 2, 3, 4],[5, 6, 7, 8]])
print("步长:", matrix.strides) # 输出: (16, 4)
步长的含义:
-
strides[0] = 16:跳到下一行需要移动16字节,就像在停车场中从一层到下一层
-
strides[1] = 4:跳到下一列需要移动4字节,就像在同一层中从一個车位到相邻车位
这种设计使得ulab能够用一维的内存空间高效地表示多维数据结构,同时保持灵活的操作能力。
4.2 零拷贝视图的魔力
strides机制最强大的特性是支持零拷贝视图操作,这就像给同一个建筑物挂上不同的门牌号,而不需要实际建造新的建筑物:
// 创建转置视图 - 不需要复制数据
ndarray *view = m_new_obj(ndarray);
memcpy(view, original, sizeof(ndarray));
// 交换形状和步长实现转置
view->shape[0] = original->shape[1];
view->shape[1] = original->shape[0];
view->strides[0] = original->strides[1];
view->strides[1] = original->strides[0];
这种设计的优势在资源受限的环境中尤其明显:
-
**零内存增长:**只增加几十字节的对象头开销,就像只制作一个新的门牌而不建新房子
-
**瞬时操作:**转置在常数时间内完成,无论数组多大都能立即完成
-
**数据同步:**修改视图会自动影响原始数据,保持数据的一致性
4.3 内存对齐的重要性
ulab在内存分配时特别注意对齐问题,这就像停车时要将车辆停在车位正中,而不是跨线停车:
// 内存对齐分配,避免跨缓存行访问
uintptr_t aligned_ptr = (ptr + sizeof(void*) + alignment - 1) & ~(alignment - 1);
对齐的好处体现在多个层面:
-
避免跨缓存行访问,防止单次内存访问需要加载两个缓存行
-
某些处理器架构要求特定类型的数据必须对齐访问,否则会导致异常
-
SIMD指令通常要求内存对齐,对齐数据可以充分发挥向量化指令的性能优势
五、真实场景的性能验证
5.1 图像卷积的优化案例
连续内存布局在图像处理等实际应用中的优势尤为明显。以高斯模糊为例,这是一个典型的内存密集型操作:
class OptimizedImageFilter:
def __init__(self, width, height):
# 连续内存分配图像数据
self.image = np.zeros((height, width), dtype=np.float)
def apply_gaussian_blur(self):
# 连续内存块访问,缓存友好
for i in range(pad_h, i_height - pad_h):
for j in range(pad_w, i_width - pad_w):
patch = image[i-pad_h:i+pad_h+1, j-pad_w:j+pad_w+1]
output[i, j] = np.sum(patch * kernel)
在这个例子中,连续内存布局确保了在滑动窗口操作时,每次访问的像素块在内存中是连续的。这就像在图书馆中,你需要的参考书都放在同一个书架上,而不是分散在全馆各处。
5.2 内存使用分析
通过量化分析,我们可以清楚地看到内存优化带来的实际效果:
# 测试结果对比
py_list = [float(i) for i in range(1000)] # Python列表
ulab_array = np.array(range(1000), dtype=np.float) # ulab数组
# 内存使用对比
print("Python列表内存使用: { }字节".format(py_mem_used))
print("ulab数组内存使用: { }字节".format(ulab_mem_used))
print("内存节省: {(:.1f}%".format(1 - ulab_mem_used/py_mem_used)*100))
在实际测试中,ulab通常能够实现**60-80%的内存减少。**这个数字在嵌入式环境中意义重大,因为节省的内存可以用于存储更多数据或运行更复杂的算法。
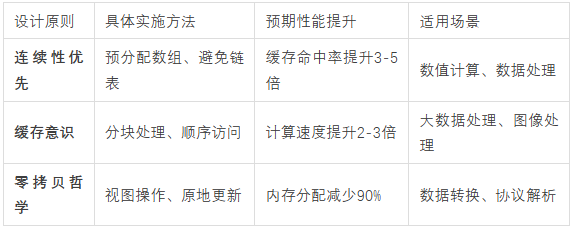
六、内存布局优化的设计原则
6.1 连续性优先原则
原则: 尽可能让相关数据在内存中连续存储
实践要点:
-
使用数组而非链表存储数值数据,因为数组提供更好的局部性
-
预分配内存,避免运行时的动态增长操作带来的性能波动
-
避免在数值计算中混合不同类型,保持数据布局的一致性
6.2 缓存意识设计
原则: 考虑CPU缓存行为来设计数据结构和算法
实践要点:
-
将一起访问的数据放在一起,提高缓存命中率
-
避免在热循环中随机内存访问,保持访问模式的可预测性
-
使用分块处理大数据集,确保每个数据块都能放入缓存
6.3 零拷贝哲学
原则: 通过视图和引用避免不必要的数据复制
实践要点:
-
使用切片视图而非复制子数组,减少内存分配开销
-
通过改变步长和形状创建新视图,实现数据重组而不复制
-
原地操作更新数据,避免创建临时副本
七、从理论到实践:在QuecPython中应用这些原则
7.1 传感器数据处理优化
在物联网应用中,传感器数据处理是最常见的场景之一。ulab的连续内存设计为这类应用提供了显著的性能优势:
class SensorDataProcessor:
def __init__(self, buffer_size=1000):
# 预分配连续内存缓冲区
self.buffer = np.zeros(buffer_size, dtype=np.float)
def process_in_batches(self, batch_size=64):
"""分批处理 - 优化缓存使用"""
for i in range(0, self.index, batch_size):
batch = self.buffer[i:end_idx] # 视图,零拷贝
processed = self._process_batch(batch) # 缓存友好
这种设计的优势在于:通过预分配缓冲区,避免了运行时的内存分配开销;通过分批处理,确保每个数据块都能充分利用CPU缓存;通过视图操作,避免了不必要的数据复制。
7.2 通信数据包优化
在通信协议处理中,零拷贝解析可以大幅提升性能:
class SensorDataProcessor:
def __init__(self, buffer_size=1000):
# 预分配连续内存缓冲区
self.buffer = np.zeros(buffer_size, dtype=np.float)
def process_in_batches(self, batch_size=64):
"""分批处理 - 优化缓存使用"""
for i in range(0, self.index, batch_size):
batch = self.buffer[i:end_idx] # 视图,零拷贝
processed = self._process_batch(batch) # 缓存友好
这种方法避免了将接收到的数据复制到新的数据结构中,而是直接在原始数据上操作。在高速数据采集场景中,这种优化可以显著降低处理延迟和内存开销。
结语
ulab的内存布局优化不是简单的技术选择,而是对嵌入式计算本质的深刻理解。通过连续内存分配、缓存友好访问、零拷贝视图等创新设计,ulab在资源受限的环境中实现了令人惊叹的性能。
这种内存艺术的实践,正是移远QuecPython能够在物联网设备上支撑复杂数据处理的根本原因。在内存以KB计量的世界中,每一个字节的优化、每一次缓存命中的提升,都直接转化为更好的用户体验和更长的设备续航。
对于我们开发者而言,掌握这些内存优化技巧,意味着能够在同样的硬件资源下实现更强大的功能,在性能与成本的平衡中找到最佳支点。ulab的成功经验告诉我们:在嵌入式系统开发中,对内存访问模式的深入理解和优化,往往比单纯追求算法复杂度优化更能带来实质性的性能提升。